去除或标记文本中的重复句段
在处理文本的过程中,比如下载的网文,经常会出现有意或无意的重复句子、段落甚至篇章。今天就以一个网络小说为例,实现网络小说错误重复文本的校对、标记和删除。
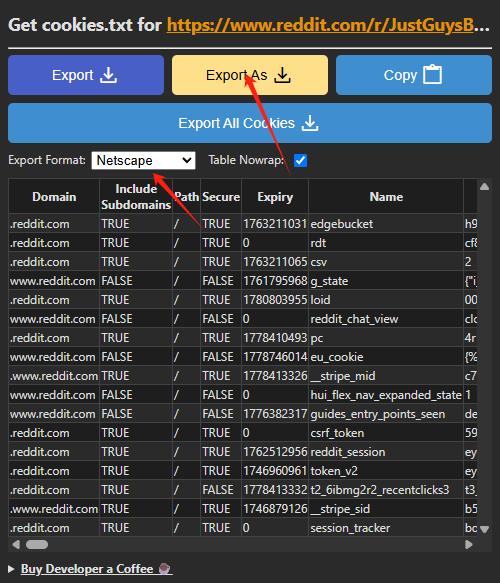
下载到《国民法医》的txt文件,目测章节、标题和内容还都正常。


很多人直接阅读TxT排版小说,对其毅力表示由衷钦佩。Ai-China是将其Ctrl+A Ctrl+C Ctrl+V 到Word中,Ctrl+H,使用通配符,查找===([一-﨩]*?)===,替换为===\1===,且在替换框中(如下图所示)选择格式-> 样式–>标题2,先做好章节标题排版。

接下来去除文本中多余空格。
观察文本,一般在是段首或段末存在多余空格,复制一下空格,还是查找替换。查找中填写刚才复制的空格,替换为空。全部替换。
然后做中文文本的首行缩进。
查找内容中,选择格式–>字体,选择五号 (即用与刚刚处理好的标题字号相区别的正文文本字号,选择正文文本)

在替换为中,选择格式–>段落,再选择缩进–>特殊–>首行,如下设置为2字符或4字符(视中文字体或英文字体而定)

点击确定,然后全部替换,完成了首行缩进。
现在的版式已经好了很多,阅读无障碍。
接下来,因为网文内容的不规范,大概率会出现很多缺失和重复内容。我们可以用查重的方式做一个批量对照处理,即用一段脚本找出文本中句段的重复,标记、删除重复,并再找出正确对应内容填充回去。
- 将刚才待处理的Word文件保存为
input.docx,最好放入一个单独的文件夹。 - 将以下代码保存为
rm.py,保存到上面同一文件夹。
1 | from docx import Document |
- 进入上述文件夹,在该文件夹内打开
cmd(点击地址栏后输入cmd即可)。 - 在程序端输入
python rm.py执行脚本,大约几秒后即可完成处理,并在同文件夹内生成一个名为output.docx的文件。打开后即可找到标记为红色高亮删除线的重复句段。(需要计算机内已安装python,安装很简单,在此不赘述) - 对照网上其他来源的文本内容,即可查重补漏,生成一篇完整完美的网文小说。
 Wechat
Wechat- Alipay
- Paypal



相关推荐
Comment
WalineGiscus