ChatTTS安装使用保姆级教程
ChatTTS,语音生成类模型新贵,主要特点在于语音语调极其自然,尤其是对话。可以添加停顿、笑声等效果,应该逐步会更加完善。
暂时只适用于中文和英文。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本。对于模型的具体介绍, 可以参考B站的 宣传视频
Ai-China也试用了一下,效果非常不错。因为使用的是多年前的老笔记本,虽有独立显卡,但仅4G显存,勉强够上最低标准,所以安装过程中碰到一些问题,分享出来,大家免踩。
该项目原作者为2noise(幽默哈,嫌自己太聒噪吗?)
不懂python之类编程的用户,可能不知如何上手。于是,有大神制作出了WebUI版本,而且贴心地提供了多种安装形式。
下面就以Windows 11系统为例,讲一下源码部署的安装过程:
-
下载Python3.9及以上版本并安装,安装时注意选中
Add Python to environment variables -
下载并安装git
-
创建空文件夹
D:/ChatTTS并进入(程序有些大,请选择有充裕空间的本地磁盘),在文件夹地址栏输入cmd回车,在弹出的cmd窗口中执行命令git clone https://github.com/jianchang512/chatTTS-ui将源项目克隆到本地 -
克隆后会在
ChatTTS文件夹下生成chatTTS-ui和venv两个子文件夹,进入chatTTS-ui后在文件夹地址栏输入cmd回车(或者直接在原cmd下执行cd chatTTS-ui) -
创建虚拟环境,执行命令
python -m venv venv -
激活虚拟环境,执行
.\venv\scripts\activate -
安装依赖,执行
pip install -r requirements.txt -
如果不需要CUDA加速(就是N卡的显卡加速,一般都会需要吧),执行
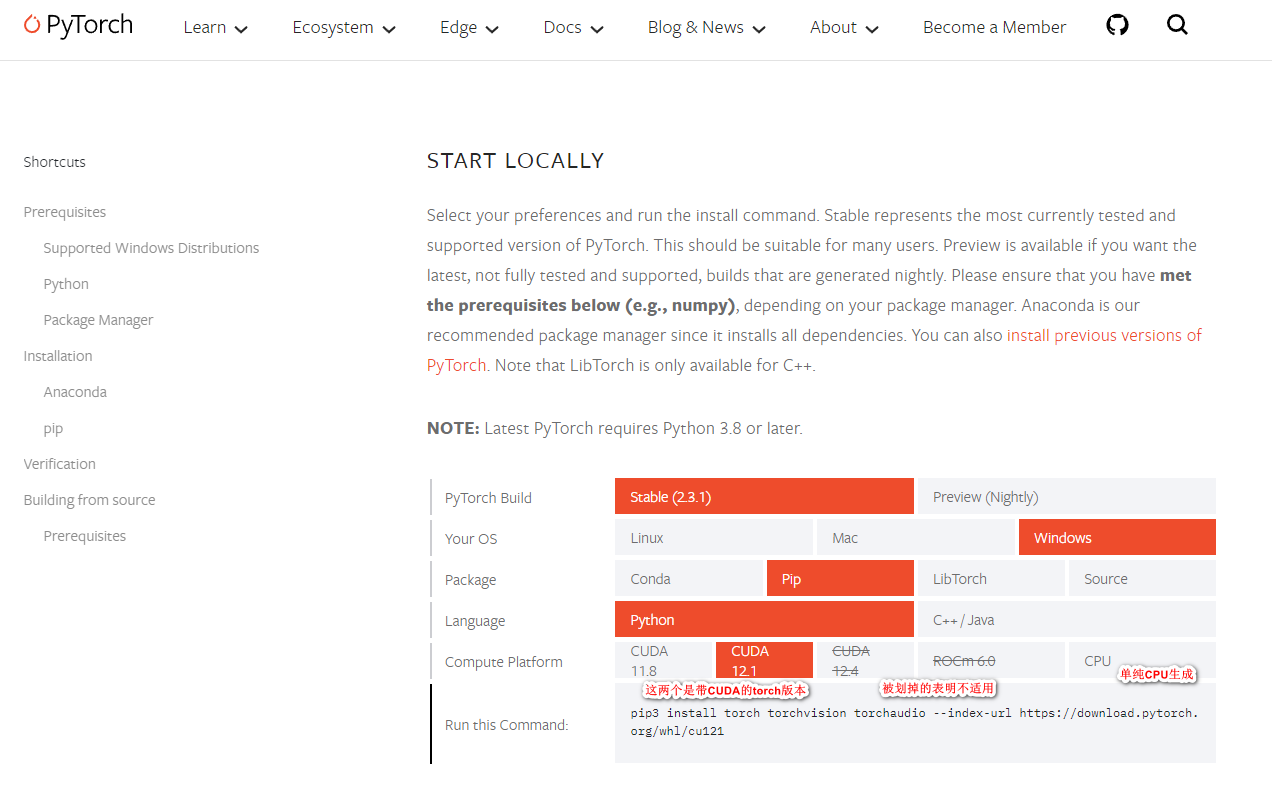
pip install torch==2.1.2 torchaudio==2.1.2如果需要CUDA加速,执行
pip install torch==2.1.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu118另需安装 CUDA11.8+ ToolKit
以下安装步骤源自:https://juejin.cn/post/7318704408727519270,有具体更改。
在window上使用一些AI工具时,经常遇到需要CUDA加速支持的情况。CUDA(Compute Unified Device Architecture,统一计算架构)是由英伟达NVIDIA所推出的一种软硬件集成技术,因为 CUDA、cudnn、显卡驱动等兼容问题,经常会出现各种各样的错误。
首先要确定你使用的是英伟达显卡(NVIDIA),也就是常说的N卡,否则安装了也无法使用。
安装 CUDA
更新显卡驱动到最新版,然后执行
nvidia-smi,查看允许安装的最大 CUDA 版本号,不可安装大于此处显示的 CUDA,比如下图,允许安装的最大 cuda 版本号,比如此处显示 11.8,那么就不能安装 cuda12.1。
首先打开 developer.nvidia.com/cuda-downlo… 网址,根据你的操作系统版本,选择对应的CUDA版本,比如下图,选择的是 x86_64 window 10操作系统,然后点击
exe[local]注意:如果当前版本大于你计算机允许的版本,比如执行了
nvidia-smi后,允许的是11.8,但此处是12.3,那么不可安装,你需要点击 developer.nvidia.com/cuda-toolki… 该链接,下载旧版本(这里注意:选择旧版本后,还需要再重新完全一次上图点选)下载完成后双击打开
然后点ok,然后在下图中,选择“自定义安装”,然后下一步
在自定义安装选项界面中只选中 “CUDA”,将其他的选中都去掉,如下图
安装完成后,默认将安装在
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1目录下,如果你安装的是11.8 版本,那么最后的v12.1改为v11.8即可,以此类推。如果安装成功但是没有这个目录,请检查是否在C:\Program Files(x86)\NVIDIA GPU Computing Toolkit\CUDA\v12.1目录下.安装 cudnn
在CUDA安装完成后,打开网址 developer.nvidia.com/rdp/cudnn-d… ,该网址可能需要登录,如果没有账号就先注册后登录。打开后,可能需要填写一份问卷,如图。
提交后到达下载页面,根据操作系统版本选择下载
下载后,双击安装,一路下一步完成
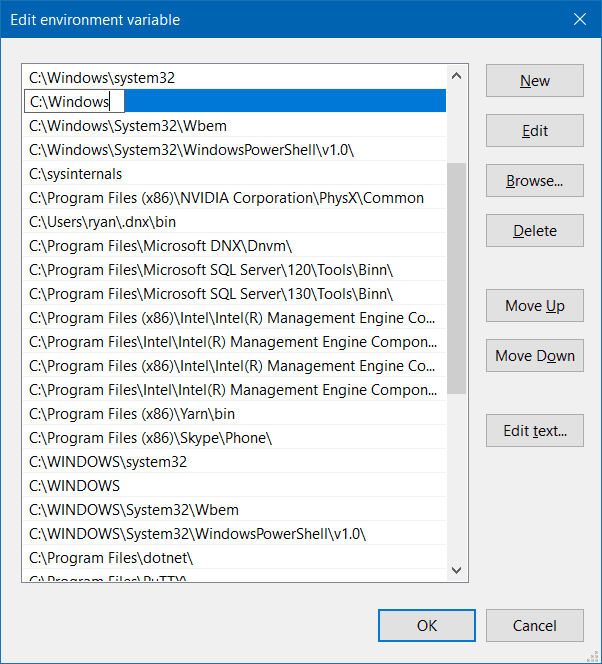
配置环境变量(可能已自动添加,如果未添加请手动添加)
按Window+键盘右上角
pause break键,打开的设置页面找到高级设置,点开找到环境变量–系统变量,添加4条记录,如下,具体版本号数字根据你安装的版本号不同。先观察是否已存在, 若存在无需添加
1
2
3
4vbnet复制代码C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\lib
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.1\libnvvp完成后的效果
安装 cuBLAS
有时会遇到“cublasxx.dll不存在”的错误,此时需要下载 cuBLAS,然后将dll文件复制到系统目录下
测试是否成功
执行
nvcc -V,成功会返回cuda版本号 -
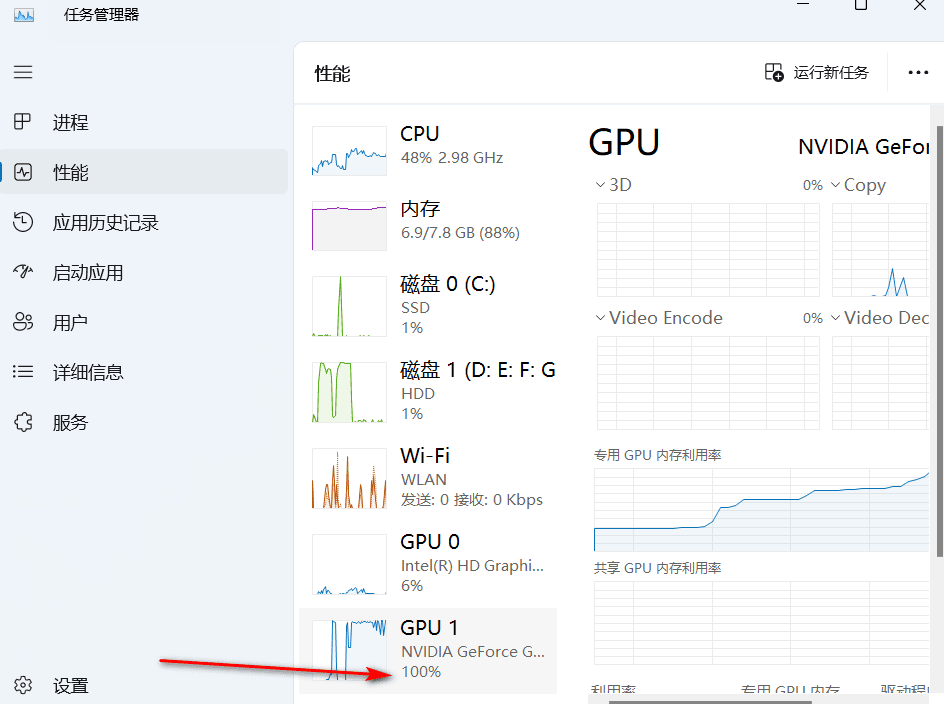
一般来讲,这个时候已经可以在cmd执行
python app.py启动并进入WebUI,开始文本转语音的TTS了。但这里还有个问题。我们都知道AI类的大模型都是依靠显卡来生成,这也是我们此前冗长准备的原因。但到了这一步,都开始生成了,却赫然发现use CPU的字样!使用CPU效率非常低,而且动不动占满100%,过程中什么其他事情都做不得,长文本更是无法完成,动不动时长以年月计。那如何才能调用GPU(也即N卡的CUDA)来生成呢?Ai-China查阅了作者的所有issue,同样问题的人很多,但试过的方法都不好用。向作者提问后,也未得到太明确的方案。
当时Ai-China就有些怀疑,是否自己的显卡过于老旧,不支持呢?但官方给出的参数却是允许4G显存的,于是又一通海搜……
终于在Twitter上发现同样的问题,而且大神给解决了!
原来是4G显存的10进制表示为 4095.75,而
ChatTTS/core.py中的device=select_device(4096)的限制是4096,下限比前者高了一点点!所以改小过来,就一切正常了。 -
此时再运行
python app.py将自动打开浏览器窗口,默认地址http://127.0.0.1:9966
(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)。魔塔是中国服务器,从这里下载不允许挂代理,但魔塔又缺少一个`spk_stat.pt`文件。于是想了个办法,改一下代理的设置。
我用的是v2rayN,`系统代理`选`pac模式`,或者找到类似的设置,将`127.0.0.1`本地设为直连不走代理即可。又或者将魔塔的相关行都注释掉,将Hugging face的相关行都注释回来,具体请参见作者页面,有详细说明。

















 (注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)。魔塔是中国服务器,从这里下载不允许挂代理,但魔塔又缺少一个`spk_stat.pt`文件。于是想了个办法,改一下代理的设置。
我用的是v2rayN,`系统代理`选`pac模式`,或者找到类似的设置,将`127.0.0.1`本地设为直连不走代理即可。又或者将魔塔的相关行都注释掉,将Hugging face的相关行都注释回来,具体请参见作者页面,有详细说明。
(注意:默认从 modelscope 魔塔下载模型,不可使用代理下载,请关闭代理)。魔塔是中国服务器,从这里下载不允许挂代理,但魔塔又缺少一个`spk_stat.pt`文件。于是想了个办法,改一下代理的设置。
我用的是v2rayN,`系统代理`选`pac模式`,或者找到类似的设置,将`127.0.0.1`本地设为直连不走代理即可。又或者将魔塔的相关行都注释掉,将Hugging face的相关行都注释回来,具体请参见作者页面,有详细说明。
- Wechat
- Alipay
- Paypal